by
by 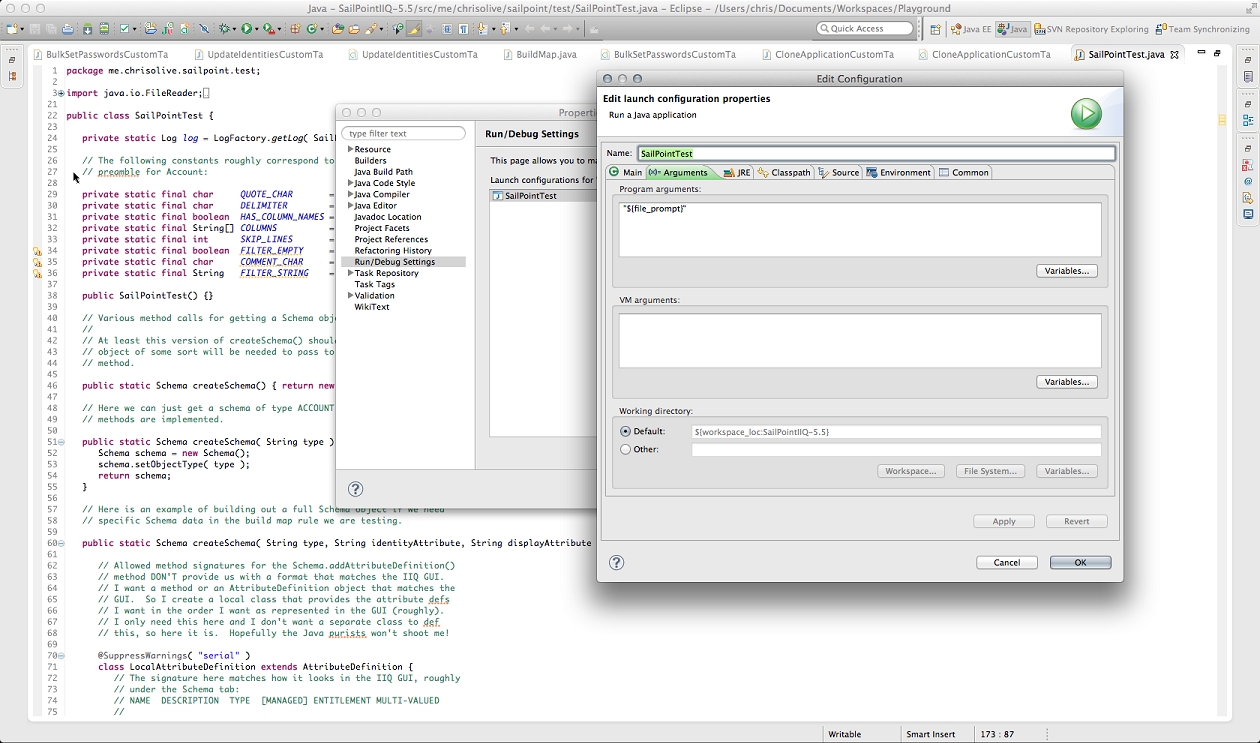
I’ve been sitting on this article and concept for months and have had others ask me about it via email — whether I’ve ever done something like this before — and well… here it is.
Tired of No BeanShell Coding Validation!
It turns out I was sitting around in my hotel room in Bangalore on India’s Independence Day last year, whacking away on some client code and doing some data modeling using CSV. I had a somewhat involved BuildMap rule I was working on and I was getting a null pointer exception I simply could not find. A few hours and one simple coding mistake later, once discovered, I was finally on my way. But it was really discouraging to know that if I had been coding in Eclipse, the coding mistake would have been spotted immediately.
The next thought I had was actually two-fold. While I have at times actually written test straps in real Java using the SailPoint IdentityIQ Java libraries (ie. jars) and dropped my BeanShell code into procedures to instantly validate the syntax, I have also wanted at some point in time to be able to simulate or partially simulate rule modeling and data modeling outside of SailPoint IdentityIQ using Java I had complete control over writing and executing.
So on this particular day, being particularly irked, I decided to combine those two wishes and see what I could do about having a place I could not only drop, for instance, BuildMap rule code into Eclipse and instantly validate it, but also execute the code I intended for SailPoint IdentityIQ against connector sources I also had connected to SailPoint IdentityIQ (in development, of course!) and see and manipulate the results.
Once I was done iterating my development over a real dataset, I could take my validated Java code, drop it back into SailPoint IdentityIQ in BeanShell and have not only validated but also working code in SailPoint IdentityIQ with very little or no modification.
Establishing SailPoint Context
One thing you will need if you want to run your Java code in an actual SailPoint IdentityIQ context outside of SailPoint IdentityIQ proper is establishing SailPointContext in your code. This, I will tell you, while not impossible, is not easy to do. You need to implement the Spring Framework and a lot of other stuff. If you are interested in doing this and have access to SailPoint Compass, you can actually read about establishing SailPointContext here4.
Since doing that much work wasn’t something I had the time for, almost immediately I decided to implement a partial simulation that would allow me to (1) model and validate my rule and (2) also allow me to model my data very simply and easily without establishing SailPointContext. I could still achieve my goal of iterating the solution to produce validated and working code to drop back into SailPoint IdentityIQ in this way.
The Code
Amazingly, the code for simulating a BuildMap rule, pointing it to the actual CSV I intend for SailPoint IdentityIQ, and simulating an account aggregation task is not that complex. Once you have the code, if you understand how SailPoint IdentityIQ works in general, you could conceivably re-engineer and simulate other segments of SailPoint IdentityIQ processing or modeling other rule types and/or data outside of SailPoint IdentityIQ1.
I’ll not place the code listing directly in the column here. But you can click here to download a text equivalent in a new browser window to follow along as I discuss the approach and sections of the code here. Or you can rename it to SailPointTest.java to modify and use it as you see fit.
Let’s Not Reinvent the CSV Wheel
The first thing you may notice in the code is I don’t have a lot of typical Java I/O code. At least none of length that I had to write.
When I first conceived of writing a simulation in Java, I didn’t want to have to reinvent opening a text file, reading in lines from the file, properly parsing those lines as per CSV rules, and so on. There had to be a better way and something already written to handle this. While there are a number of solutions out there to do this, the solution I settled upon was OpenCSV.
OpenCSV provides a very simple way to point to a CSV file, open it, read it, properly parse it and provide other methods for acting on those lines. Follow the link to OpenCSV here and read all about it. That’s all I’m going to mention about OpenCSV here.
Let’s get into some of the code next. I’ll assume you’ve downloaded a copy already and have this open in your favorite IDE to follow along.
The Preambles
First of all, let’s look at the preamble for the Java source and then we’ll talk about the “IIQ preamble” that roughly matches the options one would see, one for one, in the SailPoint IdentityIQ GUI for a DelimitedFile connector:
package me.chrisolive.sailpoint.test;
import java.io.FileReader;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import sailpoint.api.SailPointContext;
import sailpoint.connector.Connector;
import sailpoint.connector.DelimitedFileConnector;
import sailpoint.object.Application;
import sailpoint.object.AttributeDefinition;
import sailpoint.object.Schema;
import sailpoint.tools.GeneralException;
import au.com.bytecode.opencsv.CSVReader;
public class SailPointTest {
private static Log log = LogFactory.getLog( SailPointTest.class );
// The following constants roughly correspond to the IIQ DelimitedFile
// preamble for Account:
private static final char QUOTE_CHAR = '"';
private static final char DELIMITER = ',';
private static final boolean HAS_COLUMN_NAMES = true;
private static final String[] COLUMNS = { "One", "Two", "Three" };
private static final int SKIP_LINES = 0;
private static final boolean FILTER_EMPTY = true; // Not implemented here.
private static final char COMMENT_CHAR = '#'; // Not implemented here.
private static final String FILTER_STRING = ""; // Not implemented here.
public SailPointTest() {}
Notice we will need a java.io.FileReader and we’ll be catching java.io.IOExceptions in various places. Apache Commons will be used for logging — this is what SailPoint IdentityIQ uses internally. And we see as our last import the reference to the class we need for OpenCSV. We of course have to import this JAR into our project in Eclipse.
Not Really Intended for Compilation
The intention I had was to execute this code in Eclipse and see the output in the Console window. I never intended to compile this code into a .class file and use it in any way outside of the Eclipse environment. You will see shortly just how incredibly well this works with a simple parameter setting in Eclipse.
DelimitedFile Preamble
So the section of constants above roughly corresponds to the interview questions on the Account tab of the DelimitedFile connector page in the IIQ GUI, right?2 You can set a QUOTE_CHAR as in SailPoint IdentityIQ, or a DELIMITER. You can set your HAS_COLOMN_NAMES to false and then change your COLUMNS String[] array to the column names you actually want.
(And by the way, for modeling, you could just make them whatever you want, as you could in SailPoint IdentityIQ — it wouldn’t matter for modeling until you got ready to actually use them and import them as actual attributes with the correct names for your real application schema in SailPoint IdentityIQ.)

The BuildMap Rule Itself
Let’s skip ahead in the code to the section where we will or can write our BuildMap rule right in Eclipse, validate it, and run it against a real Schema object we’ve built. This is what I was really after, was this section of code:
// Here is where we actually are able to test our build map code from IIQ.
// Essentially, we can cut and paste our build map code out of IIQ into
// this area of code. If we have embedded functions in our BeanShell code
// we would have to refactor a little inside of Java and then break that
// logic back out, but essentially we can:
//
// (1) Check the logic here AND...
// (2) Use Eclipse to pick up on other errors, which we can't do in the IIQ
// editor!!
//
// Or... alternately... DEVELOP our build map rule here first and, when we
// know it works, cut and paste working code back into IIQ. :-)
@SuppressWarnings( { "unchecked", "rawtypes" } )
public static Map<String, Object> executeBuildMap( Log log, SailPointContext context, Application application, Schema schema, Map<String, Object> state, List<String> record, List<String> cols ) {
//----- Code from here can be dropped into IIQ almost without change and should be valid! -----
Map map = DelimitedFileConnector.defaultBuildMap( cols, record );
// Fix userName versus fullName issue.
String fullName = (String) map.get( "fullName" );
map.put( "userName", fullName );
fullName = fullName.replace( ".", " " );
map.put( "fullName", fullName );
// Transform the email.
String email = (String) map.get( "email" );
String newEmail = email.replace( "demoexample.com", "newcompany.com" );
map.put( "email", newEmail.toLowerCase() );
return map;
//----- End of Code we can drop into IIQ for our BuildMap rule -----
}
Simulating An Account Aggregation
Now, what we need to do is get this code running in context against the target CSV file. To do this, I simulated an SailPoint IdentityIQ account aggregation task. When an account aggregation task is run in SailPoint IdentityIQ against an application of DelimitedFile type, SailPoint IdentityIQ is going to:
(1) Open the file.
(2) Read in the records a line at a time.
(3) Run the BuildMap rule against every record.
So that is simulated here:3
// Here is an aggregate account task method. It doesn't really represent
// a task as it is implemented in IIQ, but logically, this is about what
// happens in order to aggregate an account CSV. The CSV file has to be
// opened and read and the build map executed for every line in the file.
// Even state is implemented here!
public static void taskAggregateAccount( String csvFilename ) throws GeneralException, IOException {
// Suck in CSV file records using OpenCSV reader object. Correctly
// handles reading a CSV file with embedded delimiters inside of
// a designated quoted character, etc. Simple.
//
// Notice how the OpenCSV implementation dovetails nicely with some
// of the IIQ preamble items (constants) we've defined as from the
// IIQ GUI. :-)
CSVReader reader = new CSVReader( new FileReader( csvFilename ), DELIMITER, QUOTE_CHAR, SKIP_LINES );
List<String[]> records = reader.readAll();
reader.close();
// Null SailPoint context. Establishing a real, live SailPointContext
// object is, well... a bit of work, pretty much requires using the
// Spring framework, and in most cases, especially for simple rules
// modeling, isn't going to be needed, SOOOO... we chicken out. :-)
SailPointContext context = null;
// Setup application and schema. This is mainly dummied out for now as
// we don't have a real live SailPointContext in this example.
//
// We *can* select at present from a number of Schema object creation
// methods, but any schema information would have to be programatically
// filled out as shown above.
Application application = new Application();
Schema schema = createSchema( Connector.TYPE_ACCOUNT, "Username", "Fullname" );
System.out.println( schema.toXml() );
// Set state. At the beginning of the aggregation, it's empty.
Map<String,Object> state = new HashMap<String, Object>();
// Determine columns we are using. We can use the columns based on the
// first (readable) line in the file (relative to SKIP_LINES), or we can
// use our designated static COLUMNS just like we can in IIQ.
List<String> columns = Arrays.asList( COLUMNS );
if (HAS_COLUMN_NAMES) {
columns = Arrays.asList( records.get( 0 ) );
records.remove( 0 );
}
// Here, we execute our build map for every record in the input CSV file.
// Anything we want to do after executing the build map, which... returns
// a Map instance just like in IIQ... we can do right after the
// executeBuildMap() call.
//
// This gives us a bit more flexibility that seeing the ResourceObject
// painted to the screen as in ConnectorDebug. I can construct the
// output here to suit:
for (String[] record : records) {
Map<String,Object> returnMap = executeBuildMap( log, context, application, schema, state, Arrays.asList( record ), columns );
// For now, I just show key/value pairs from the return map itself:
System.out.println( "-----" );
for (String key : returnMap.keySet())
System.out.println( "Key: " + key + " Value: " + returnMap.get( key ) );
}
}
This section of code is a great place to open the CSV file using OpenCSV and create the object instances we need to pass into the executeBuildMap() method that it requires, at least for the code we’ve planted in that method.
If we needed an actual SailPoint Schema object (and I’ve used the Schema object before in aggregation rules), because we don’t have SailPointContext established, we’d have to build out the Schema object on our own.
It turns out, I’ve provided some methods for establishing a Schema object that makes that task fairly trivial:
// Various method calls for getting a Schema object.
//
// At least this version of createSchema() should be called as a Schema
// object of some sort will be needed to pass to the executeBuildMap()
// method.
public static Schema createSchema() { return new Schema(); }
// Here we can just get a schema of type ACCOUNT or GROUP (once group
// methods are implemented.
public static Schema createSchema( String type ) {
Schema schema = new Schema();
schema.setObjectType( type );
return schema;
}
// Here is an example of building out a full Schema object if we need
// specific Schema data in the build map rule we are testing.
public static Schema createSchema( String type, String identityAttribute, String displayAttribute ) {
// Allowed method signatures for the Schema.addAttributeDefinition()
// method DON'T provide us with a format that matches the IIQ GUI.
// I want a method or an AttributeDefinition object that matches the
// GUI. So I create a local class that provides the attribute defs
// I want in the order I want as represented in the GUI (roughly).
// I only need this here and I don't want a separate class to def
// this, so here it is. Hopefully the Java purists won't shoot me!
@SuppressWarnings( "serial" )
class LocalAttributeDefinition extends AttributeDefinition {
// The signature here matches how it looks in the IIQ GUI, roughly
// under the Schema tab:
// NAME DESCRIPTION TYPE [MANAGED] ENTITLEMENT MULTI-VALUED
//
// We left out MANAGED in this signature:
public LocalAttributeDefinition( String name, String type, String description, boolean entitlement, boolean multi ) {
this.setName( name );
this.setType( type );
this.setDescription( description );
this.setEntitlement( entitlement );
this.setMulti( entitlement );
}
}
// Get a schema instance, set it's type, identity attribute and display
// attribute.
Schema schema = new Schema();
schema.setObjectType( type );
schema.setIdentityAttribute( identityAttribute );
schema.setDisplayAttribute( displayAttribute );
// Here, we build our custom schema. It's not used in our example, but
// we throw in a few attributes to show how to build out each attribute:
schema.addAttributeDefinition( new LocalAttributeDefinition( "Username", AttributeDefinition.TYPE_STRING, "", false, false ) );
schema.addAttributeDefinition( new LocalAttributeDefinition( "FullName", AttributeDefinition.TYPE_STRING, "", false, false ) );
schema.addAttributeDefinition( new LocalAttributeDefinition( "CostCenter", AttributeDefinition.TYPE_STRING, "", false, true ) );
// Return the schema we built.
return schema;
}
But at some point, without having access to a running and established SailPointContext, we may reach a point of diminishing returns in having to hand code all the objects SailPoint IdentityIQ has floating around in a live system.
But for doing simple rule and data modeling, this works great.
Tying It All Together
So now we have a working program in real Java that:
(1) Calls a taskAggregateAccount() method.
(2) That method opens a CSV file based on args[0] and
(3) Establishes all the objects we need in the executeBuildMap() method parameter list so our rule can run.
(4) If we need an object instance filled out, we have to create those objects ourselves outside of SailPointContext — and I have an example of that in creating a Schema object by hand.
All we need to do now is tie this into our Eclipse session by telling Eclipse how to ask for args[0] and Eclipse will prompt us for the CSV file anywhere on our local hard drive, pass it as args[0] and run the BuildMap rule we wrote against the CSV file we choose.
We do this by establishing a ${file_prompt} variable in Eclipse for the current project arguments. When Eclipse sees this, it will open a dialog box on your local machine and allow you to select the CSV file. It then passes that file as args[0] to your code.
To do this, open your Eclipse project properties, edit your Run/Debug Settings, setup a configuration for your run, and establish the ${file_prompt} variable like this:

Now we have seamless integration in the IDE between the local file system and OpenCSV. We see the output from the CSV in our Eclipse console window and we have a simple but working system for modeling data and rules in Java that we can better integrate into SailPoint IdentityIQ with fewer errors.
Conclusion
This should demonstrate how to use Java and the SailPoint IdentityIQ Java libraries to write meaningful code outside of SailPoint IdentityIQ. I hope this helps. I’ve had a number of people ask me about this and I even saw someone ask about this on SailPoint Compass today as I was writing this article. 🙂
From rainy downtown Minneapolis, MN USA! I hope to see you all at Navigate next week!
______________________________
Footnotes
1: Depending on how involved you want to get, however, you can begin to question the value of going too far with this concept. If individuals were able to reverse engineer SailPoint IdentityIQ simply based on observed functionality, no one would need to actually purchase SailPoint IdentityIQ, which of course is ridiculous — don’t let the ease of setting up and actually running SailPoint IdentityIQ fool you. They say simplicity comes based on abstracted-away complexity. That is certainly true of SailPoint IdentityIQ. Ease of use, setup and configuration comes due to hidden-away complexity.
2: This was based on the DelimitedFile connector interview page found in SailPoint IdentityIQ v6.0p4. There are some pretty significant changes to that page as of SailPoint IdentityIQ v6.2, but for our purposes and any future purposes, likely completely insignificant.
3: I say “simulated” because this is what it “looks like” the account aggregation task in SailPoint IdentityIQ does. Internally, it’s quite a bit more complex in terms of implementation.
4: You must have a SailPoint Compass account to see this content as it’s copyrighted material to SailPoint. Also, check out John Ruffin’s excellent article on establishing SailPointContext and doing test-driven SailPoint IdentityIQ development in Java here.